Capítulo 7 Resultados
Utilizando las imágenes:
Imagen correspondiente al año 2004 (LANDSAT/LT05/C01/T1_SR/LT05_003069_20040814)
Imagen correspondiente al año 2018 (LANDSAT/LC08/C01/T1_SR/LC08_003069_20180906)
7.1 Puntos de Entrenamiento
Elaboramos la distribución de puntos de entrenamiento para hacer la correcta discriminación de las clases fijadas en nuestro trabajo (forest, damaged forest, water) como se muestra en la siguiente figura: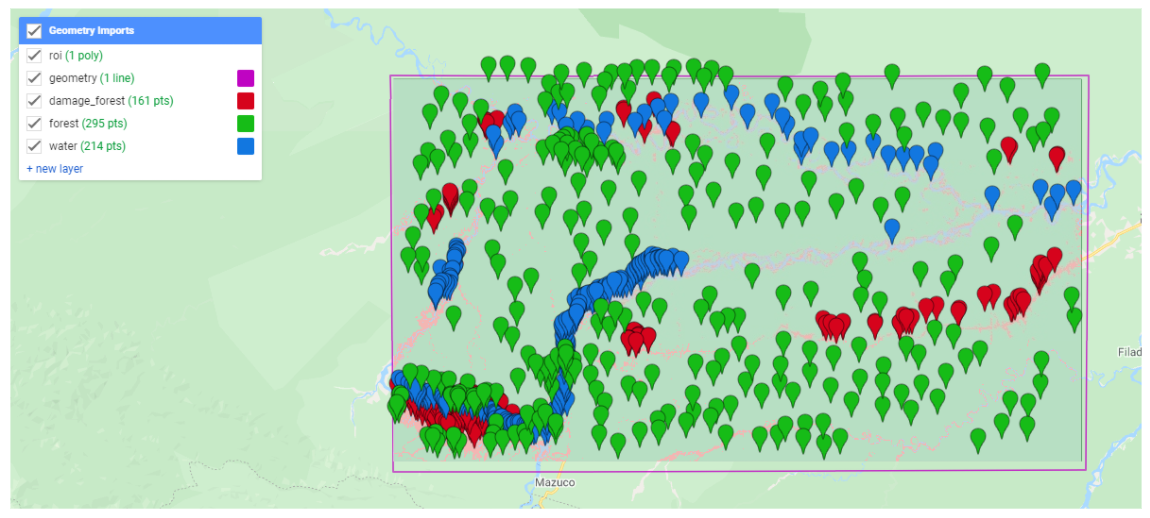
Figure 7.1: Puntos de Entrenamiento
| Clase | Cantidad de puntos |
|---|---|
| Water | 267 |
| Forest | 337 |
| Damaged Forest | 236 |
7.2 Clasificación Supervisada
Las técnicas de clasificación de imágenes satelitales se utilizan para agrupar pixeles con valores similares en varias clases. En la clasificación supervisada, se parte con una serie clases previamente predefinidas (sitios de entrenamiento). El algoritmo de clasificación de imágenes usa los sitios de entrenamiento para identificar las coberturas de suelo en la imagen completa. Como sitios de entrenamiento se van a utilizar los polígonos empleados anteriormente para la obtención de los perfiles espectrales.
El código realizado fue hecho dentro de la plataforma Google Earth Engine y lo pueden encontrar en el siguiente link:
– Código Bahuaja Sonene - Gonzales y Herrera.
Como su propio nombre indica, Random Forest consiste en una gran cantidad de árboles de decisión individuales que operan como un conjunto. Este algoritmo puede ser menos sensible al ruido y puede ser más eficiente que otros clasificadores no paramétricos de uso común, como las máquinas de soporte vectorial (Pelletier et al., 2016). Se han utilizado 1510 puntos ubicados uniformemente dentro de todo el área de estudio. El mapa de clasificación predicho mediante el modelo obtenido por el algoritmo Random Forest se muestra a continuación:
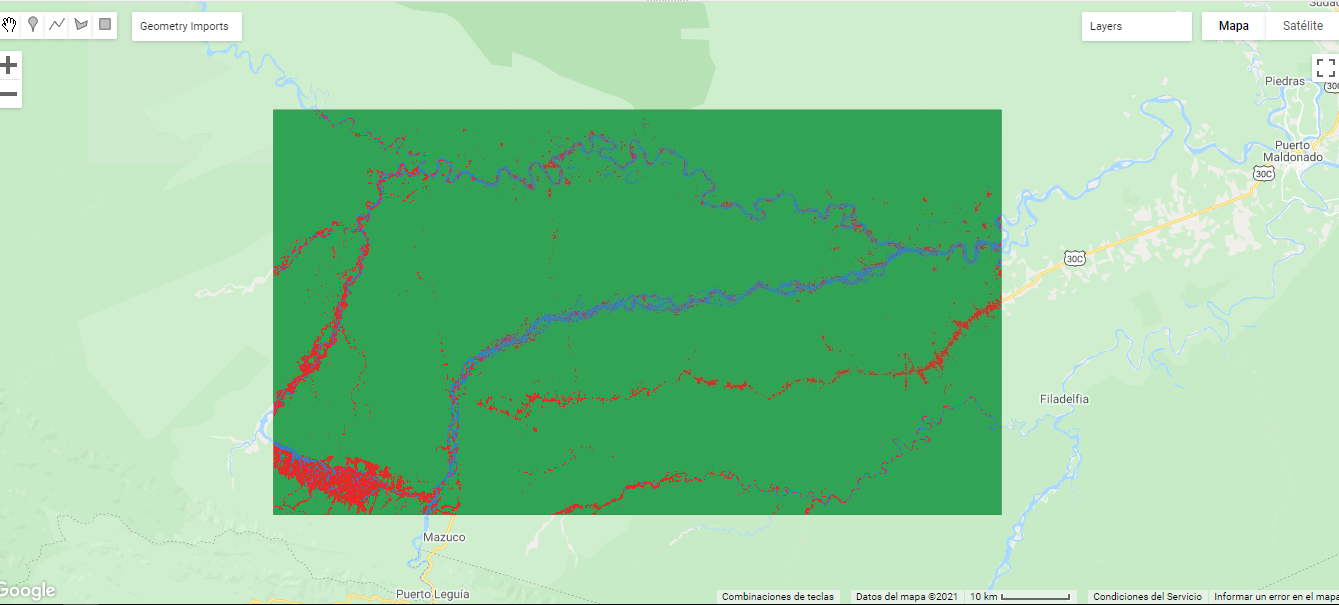
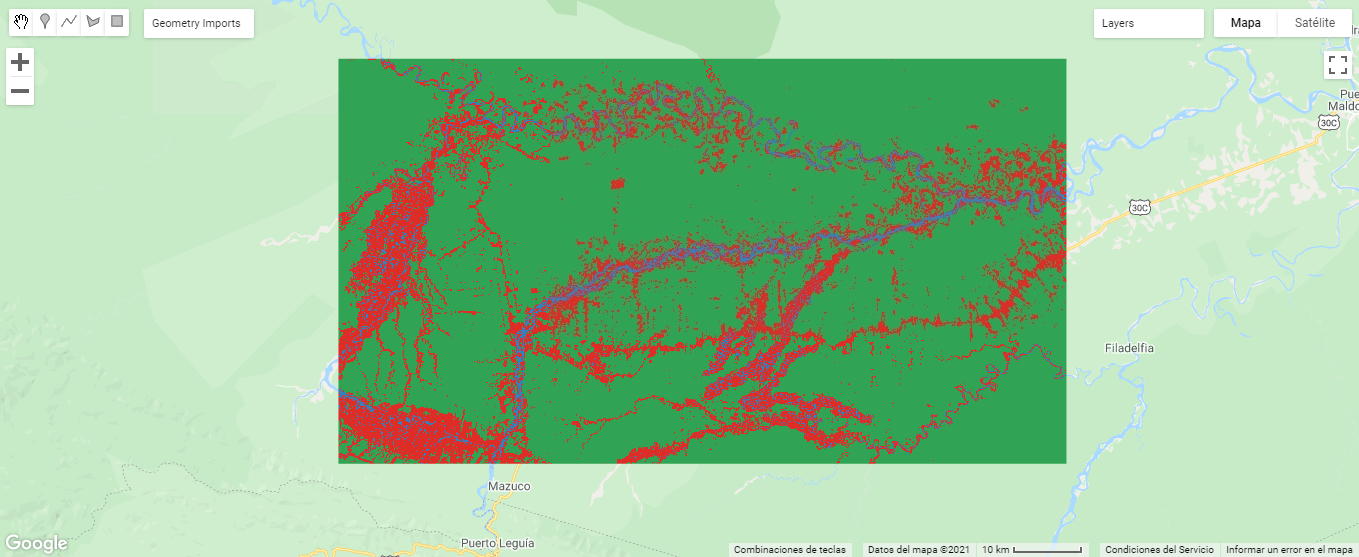 Fuente: Elaboración Propia. Izquierda (Imagen Clasificada 2004); Derecha (Imagen Clasificada 2018)
Fuente: Elaboración Propia. Izquierda (Imagen Clasificada 2004); Derecha (Imagen Clasificada 2018)
7.3 Grado de Precisión de la Clasificación
La evaluación de precisión es el paso final en el análisis de los datos de teledetección. Ayuda a verificar la precisión de los resultados obtenidos. Se ha elegido la precisión general, el coeficiente Kappa y la precisión del productor y del usuario como evaluaciones cuantitativas para determinar la precisión final de la clasificación supervisada de la cubierta terrestre.
7.3.1 Overall Acuraccy (OA)
La precisión general es la medida de precisión más simple y una de las más populares. Se calcula dividiendo el el número total de píxeles clasificados correctamente (es decir, la suma de la diagonal principal) por el número total de píxeles en la matriz de confusión (Congalton, 1991).
\[ Overall\ Accuracy\ (OA)=\frac{\sum{Diagonal}}{\sum{matrix}} \]
7.3.2 Índice Kappa
Esta evaluación corrige la precisión general de las predicciones del modelo por la precisión que se espera que ocurra por casualidad: \[ Kappa\ (K)=\frac{Overall\ accuracy-Chance\ Agreement}{1-chance\ agreement} \] Overall Accuracy = Determinado por la diagonal principal de la matriz de confusión
Chance Agreement = Suma del producto de los totales de cada fila y columna divididos por el número total de pixeles muestreados para cada clase.
7.3.3 Precisión del productor y del usuario
Se produce un error de clasificación cuando a un pixel perteneciente a una clase se le asigna una clase distinta. La precisón del Productor mide errores de omisión, es decir, cuando se excluye un pixel de la categoría que está siendo evaluada. En cambio, la precisión del usuario mide los errores de comisión, esto es, cuando se incluye un pixel incorrectamente en la categoría que está siendo evaluada.
La precisión del productor (PA) se obtiene de dividir el número de píxeles correctamente clasificados en cada categoría (diagonal principal de la matriz de confusión) por el número de píxeles de referencia de esa categoría (el total de la columna): \[ Productor\ accuracy\ (PA)=\frac{Diagonal}{\sum{col}} \] Donde:
- Diagonal = Valor de la columna perteneciente a la diagonal principal de la matriz de confusión
- ∑col = Suma de cada columna de la matriz de confusión
Mientras que la precisión del usuario (UA) se calcula dividiendo el número de píxeles correctamente clasificados en cada categoría por el número total de píxeles que se clasificaron en esa categoría (el total de la fila): \[ User\ accuracy\ (UA)=\frac{Diagonal}{\sum{row}} \] Donde:
- Diagonal = Valor de la fila perteneciente a la diagonal principal de la matriz de confusión
- ∑row = Suma de cada fila de la matriz de confusión
7.4 Valores obtenidos de la Clasificación Supervisada
A continuación adjuntamos el grado de precisión alcanzados con la clasificación supervisada utilizando el algoritmo de Random Forest.
- Tabla de valores para la imagen del 2004
| Imagen 2004 | Resultado (R.F) |
|---|---|
| OA | 0.97 |
| Kappa | 0.95 |
| Producers Acuraccy | 0.95 |
| Ucers Acuraccy | 0.96 |
- Tabla de valores para la imagen del 2018
| Imagen 2018 | Resultado (R.F) |
|---|---|
| OA | 0.94 |
| Kappa | 0.91 |
| Producers Acuraccy | 0.90 |
| Ucers Acuraccy | 0.92 |
7.5 Comparación de la superficie perdida
Obtenida la clasificación, a continuación calculamos el área de las clases correspondientes para dar a mostrar de manera cuantitativa la varación en lo que respecta a cobertura vegetal; en la siguiente tabla podemos apreciar los valores hallados:
| Área 2004 (km^2) | Área 2018 (km^2) | Variación (km^2) | |
|---|---|---|---|
| Bosque | 6086.1 | 5262.9 | -823.2 |
| Bosque dañado | 252.6 | 1018.8 | +766.2 |
| Río | 174.2 | 231.2 | +56.8 |
- Área total estudiada: 6 512.9 kilómetros cuadrados